Key Fundamentals of AI Development | 2026 Guide

Apr 24, 2026

Read in 9 Minutes
Table of Contents
- Introduction
- What AI Development Actually Means for Business Leaders
- The AI Development Lifecycle at a Glance
- The 6 Core Fundamentals of AI Development
- Where AI Development Creates Business Value: Use Cases by Function
- Build vs. Buy vs. Hybrid: Which AI Development Model Fits Your Business
- AI Development Pricing: What Does It Actually Cost?
- ROI of AI Development: What the Numbers Show
- Risks and Challenges in AI Development
- AI Development Vendor Selection: An Executive Checklist
- Top Tools and Platforms Used in AI Development
- Emerging AI Development Trends Shaping Enterprise Strategy in 2026
- Why Tibicle LLP Is a Practical Choice for AI Development
- Conclusion
- Frequently Asked Questions
Introduction
Ninety-five percent of generative AI pilots are failing. That figure comes from a 2025 MIT report, and it tells a very specific story: most organizations are investing in AI development without understanding what it actually takes to build systems that work at scale.

For C-level leaders, AI development is not fundamentally a technical question. It is a capital allocation decision. Every choice from data strategy to model architecture to vendor selection carries direct implications for cost, timeline, and competitive positioning. Menlo Ventures estimated that enterprises invested $18 billion in AI infrastructure in 2025 alone. That is not R&D spend. That is production commitment.
This guide breaks down the core fundamentals of AI development: what each stage costs, where value is actually created, and what separates deployments that scale from those that stall at the pilot stage.
What AI Development Actually Means for Business Leaders
Strip away the engineering definitions, and AI development is the process of building systems that take data in and produce decisions, predictions, or outputs that replace or augment manual effort. That is the working definition that matters for resource allocation and strategic planning.
It is not the same as buying software. Off-the-shelf tools offer fixed behaviors. AI development, whether custom or semi-custom, creates systems that learn from your specific data, adapt to your specific domain, and produce outputs calibrated to your operational context. The implication: the quality of what you put in determines the quality of what comes out.
The AI Development Lifecycle at a Glance

One of the most common reasons AI projects stall is that teams skip foundational stages or treat them as formalities. Understanding the full AI development workflow, not just the model training phase, is what separates projects that reach production from those that consume budget without delivering outcomes.
Stage 1: Problem Definition and Business Case Framing
Every AI development engagement should begin with a precisely defined problem statement tied to a measurable business metric. Vague objectives like “make customer service smarter” produce vague deliverables. Effective framing specifies: what decision or task the AI will automate or augment, what the baseline performance looks like today, what a meaningful improvement in that metric is worth in dollars, and what data currently exists to support training.
This stage is where most internal AI pilots fail before a single line of code is written. If the business case cannot survive scrutiny here, no amount of engineering excellence will save it downstream.
Stage 2: Data Discovery and Readiness Assessment
Data readiness is the most underestimated risk in AI development. Before any model work begins, the team audits available data across four dimensions: volume (is there enough labeled data to generalize?), quality (how much cleaning is required?), accessibility (is data siloed in legacy systems?), and sensitivity (does it contain PII that constrains training usage?).
Organizations that surface data readiness gaps early avoid the most expensive failure mode: discovering mid-build that the training data is insufficient, biased, or inaccessible.
Stage 3: Model Selection and Architecture Design
Model selection is a matching problem, not a prestige contest. Development teams evaluate model type (supervised, unsupervised, reinforcement learning), required explainability, compute constraints at production workload, and integration requirements. For enterprise AI solutions, architecture design also includes decisions about whether to fine-tune a foundation model, build on top of an API, or train from scratch, a decision with high cost and IP implications.
Stage 4: Data Pipeline Construction
The data pipeline is the infrastructure that moves, transforms, and serves data to the model. It handles ingestion from multiple source systems, transformation and normalization, labeling (for supervised learning), versioning (so training runs are reproducible), and serving at inference time with acceptable latency. Pipeline failures at inference time are a leading cause of post-deployment performance degradation, especially when production data drifts from training data.
Stage 5: Model Training and Iterative Evaluation
Training is one step in a longer sequence, and its cost is increasingly predictable. The more variable cost is evaluation: iterating on architecture, hyperparameters, and training data to achieve acceptable performance across business-relevant test cases. A model with 97% accuracy that performs poorly on the 3% of cases carrying the highest business risk may be worse than a simpler rule-based system.
Stage 6: Integration and Pre-Production Testing
Before deployment, the model is integrated into existing systems and tested under conditions that approximate production workload. Integration testing validates that model output connects correctly to downstream systems. Load testing validates inference cost and latency at production scale. Regression testing establishes a baseline to detect model decay after deployment.
Stage 7: Deployment and Monitoring Infrastructure
Deployment activates the model in production and begins the cost-recovery phase. MLOps infrastructure deployed here determines whether the organization can maintain performance over time. Monitoring dashboards track prediction accuracy against real-world outcomes, alert on data drift, and trigger retraining workflows when performance degrades below the defined threshold.
Organizations that skip or underinvest in monitoring consistently discover model decay as an unbudgeted cost, often after degradation has already affected customer outcomes or business metrics.
AI Development Workflow Summary
Problem Definition → Data Readiness → Model Selection → Pipeline Build → Training & Evaluation → Integration Testing → Deployment & Monitoring
The 6 Core Fundamentals of AI Development
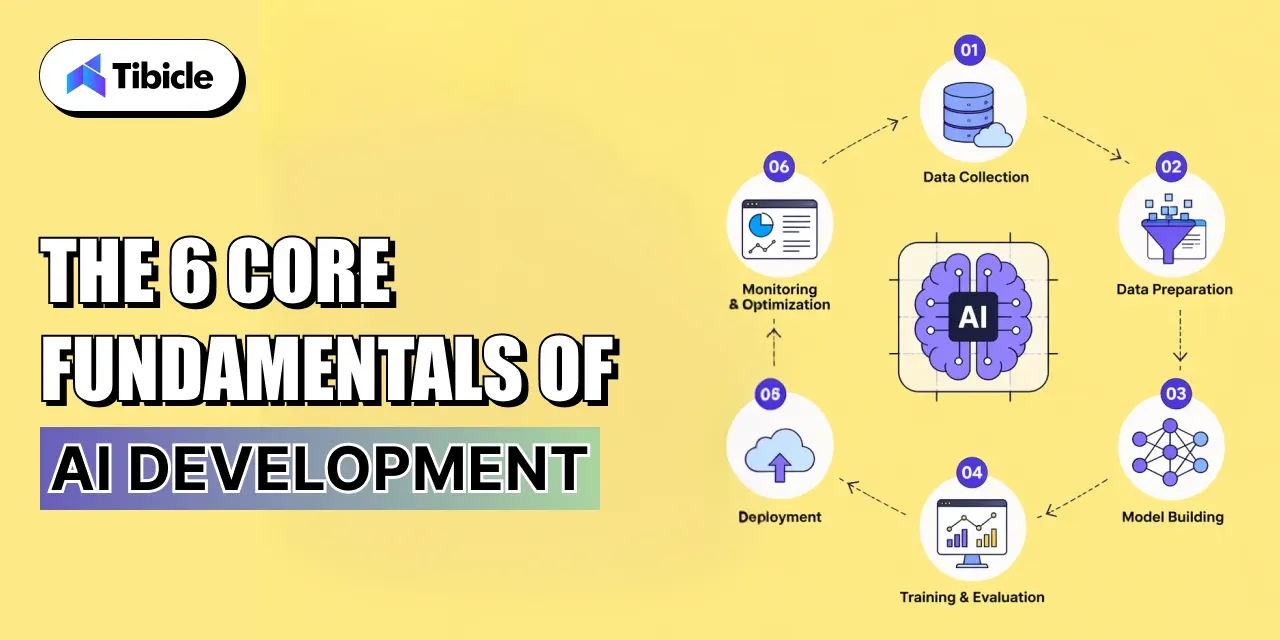
Most AI projects do not fail because of weak algorithms. They fail because one or more of the following fundamentals is misunderstood, underfunded, or skipped entirely. Each represents a discrete risk surface that executives should pressure-test before green-lighting investment.
1. Data Strategy and Pipeline Design
Model output quality is a direct function of data quality. Before any model is selected or trained, organizations need a clear view of the data they hold, its structure, and the cost of cleaning and labeling it. Structured data, such as databases and spreadsheets, is faster to work with. Unstructured data, such as documents, audio, and images, typically requires more expensive preprocessing. The data pipeline, the infrastructure that moves, cleans, and serves data to the model, is often the most expensive component to build and the least glamorous to explain to a board.
2. Model Selection (Supervised, Unsupervised, Reinforcement Learning)
Choosing the right model type requires matching the method to the business problem, not to whatever approach is generating the most industry coverage. Supervised learning works for problems with labeled historical outcomes, such as fraud detection or churn prediction. Unsupervised learning is suited to pattern discovery in unlabeled datasets. Reinforcement learning applies to optimization problems in which the system learns through trial and error. Defaulting to large language models or deep learning architectures without validating fit is one of the most common and expensive missteps in machine learning development.
3. Model Training and Evaluation Frameworks
Training a model is only half the work. Evaluation frameworks determine whether the model is actually useful in production conditions. Key concerns include overfitting, where the model performs well on training data but fails on new inputs; bias in training data that produces discriminatory or systematically wrong outputs; and accuracy benchmarks that are meaningful for the specific business problem. A model with 95% accuracy that is wrong about the 5% of the highest-risk cases may be worse than no model at all, depending on the use case.
4. Infrastructure and Scalability
The infrastructure decision cloud, on-premise, or hybrid determines both upfront cost and long-term run cost. Cloud offers flexibility and faster time to value, but can produce significant cost surprises at scale. On-premise offers cost control but requires significant upfront capital and internal expertise. A critical insight from AppInventiv’s 2025 analysis: run-cost drift is now the primary post-deployment risk for enterprise AI systems. Models that perform at an acceptable cost during testing can become prohibitively expensive under production workload. This is where MLOps discipline becomes non-negotiable.
5. AI Governance and Compliance
Governance is not a post-launch consideration. Organizations that treat compliance as a final checklist consistently find themselves abandoning projects after significant investment. Sixty-five percent of organizations have abandoned AI projects due to governance failures, according to Shakudo. The core concerns are bias detection, data privacy, particularly for models trained on personal or sensitive data, and regulatory exposure that varies significantly by industry and geography. As AI regulation matures globally, governance frameworks built during development are significantly cheaper to maintain than those retrofitted afterward.
6. AI Deployment and Ongoing Monitoring
Deployment marks the beginning of the cost recovery phase, not the end of investment. Models require retraining as data distributions shift over time, a phenomenon called model decay. Version control, rollback procedures, and AI model deployment monitoring infrastructure are operational requirements, not optional enhancements. Organizations that do not plan for retraining cycles before deployment consistently discover them as unbudgeted costs after launch.
Where AI Development Creates Business Value: Use Cases by Function
AI development delivers measurable business value across multiple organizational functions. The key is identifying where automation or augmentation yields the greatest return relative to the complexity and cost of implementation.
Operations and Process Automation
AI systems can automate high-volume, rules-based workflows, including invoice processing, logistics optimization, quality control, and supply chain forecasting. The ROI case is typically strong because the baseline manual labor cost is easy to measure, and the replacement cost is fixed. Neural networks and deep learning architectures are commonly used for image-based quality inspection and document processing at scale.
Customer Intelligence and Predictive Analytics
Predictive analytics models transform customer behavior data into actionable signals: churn risk, purchase propensity, support ticket deflection, and next-best-action recommendations. These systems work on both structured CRM data and unstructured inputs like support transcripts processed through natural language processing (NLP) pipelines. McKinsey’s 2025 data shows that 42% of organizations now apply AI in sales and marketing, the highest adoption rate of any business function.
Product Development and Feature Enhancement
AI development increasingly feeds directly into product roadmaps. Organizations are embedding recommendation engines, personalization layers, search intelligence, and content generation capabilities into customer-facing products. The distinction between “AI project” and “product feature” is increasingly meaningless. AI capability is becoming table stakes in competitive product categories.
Build vs. Buy vs. Hybrid: Which AI Development Model Fits Your Business
The most consequential AI decision most executives will make is not about which model to use. It is about the operating model for AI development itself. Each approach carries distinct tradeoffs across control, speed, cost, and risk.
Comparison Table:
| Factor | Build In-House | Buy Off-Shelf | Hybrid Model |
| Control | High | Low | Medium |
| Time to Value | 12–24 months | 1–3 months | 4–9 months |
| Cost | High upfront | Subscription-based | Shared |
| Customization | Full | Limited | Moderate |
| Risk | Talent-dependent | Vendor lock-in | Balanced |
| Best For | Core IP products | Standard workflows | Most enterprises |
Key Decision Criteria for C-Suite
Three questions determine the right approach for any given initiative. First, how strategically important is this use case? Does it differentiate your core product, or is it a supporting workflow? Second, what is your organization’s actual depth of ML talent? Overstating internal capability is the leading cause of build-in-house failures. Third, what are your data sensitivity and sovereignty requirements? Some regulated industries or competitive environments make sharing training data with third-party vendors unacceptable, which effectively eliminates or constrains off-the-shelf options.
Not sure which model fits your roadmap? Tibicle LLP helps enterprises map the right AI development approach before committing budget. Book a scoping call
AI Development Pricing: What Does It Actually Cost?
Cost transparency is one of the most common gaps in the vendor landscape. Most organizations approach AI development pricing without a framework for evaluating whether a given quote reflects the actual scope of what they need built and maintained.
Pricing Models Explained
Fixed price contracts are predictable and well-suited to clearly scoped proof-of-concept projects where requirements are stable. The risk is that AI development is rarely fully predictable, scope changes during model training and evaluation are common, and fixed-price structures often create adversarial dynamics when they occur.
Time and materials contracts are flexible and suited to iterative development where requirements evolve. The risk is a cost overrun without strong milestone governance. This model works best when the buyer has internal technical oversight capability.
Managed AI services are subscription-based, ongoing arrangements that include model maintenance, retraining, and monitoring. These are increasingly common for organizations that want to operationalize AI without building an internal MLOps capability.
Typical Cost Ranges by Project Type
| Project Type | Estimated Cost Range |
| AI chatbot / NLP tool | $15,000 – $80,000 |
| Custom ML model | $50,000 – $250,000 |
| Enterprise AI platform | $300,000+ |
| Ongoing MLOps/maintenance | $5,000–$25,000/month |
Note: Figures are directional. Scope, region, and vendor all affect final pricing significantly.
Hidden Costs Executives Miss
Four cost categories are consistently absent from initial vendor proposals. Inference cost at scale, what it costs to run the model on production workloads, frequently surprises organizations that only saw training costs in the contract. Retraining cycles, required to maintain model accuracy as real-world data evolves, are ongoing and non-trivial. Compliance integration adds cost that varies by regulatory environment. Internal change management, the organizational work of getting teams to actually use and trust AI outputs, is rarely in scope but is often what determines whether the deployment achieves its business objectives.
ROI of AI Development: What the Numbers Show

ROI from AI development is real, but it requires a clear and disciplined approach, something many organizations overlook during the excitement of the build phase. To measure impact accurately, both hard and soft returns should be tracked separately, and a proper baseline must be defined before development begins rather than reconstructed afterward.
Hard ROI vs. Soft ROI
Hard ROI includes labor cost reduction from automation, faster cycle times in processing-intensive workflows, and measurable error reduction in high-volume decisions. Soft ROI includes decision speed, competitive positioning, and talent retention in organizations where AI capability signals a forward-thinking culture. HypeStudio’s 2025 research places the typical range for AI development ROI at 150–500% over two to five years, a wide range that reflects the significant variance in how well projects are scoped and governed.
Why 42% of AI Projects Are Being Abandoned
42% of companies abandoned most of their AI projects in 2025, up sharply from 17% in 2024. The acceleration suggests that the gap between pilot enthusiasm and production reality is widening, not narrowing. (S&P Global)
The causes are consistent across industries. Unclear value definition at project initiation means there is no agreed baseline to measure against. Poor data readiness, discovering mid-build that the training data is insufficient, biased, or inaccessible, is the most operationally disruptive failure mode. Governance arriving too late, after the model architecture is already set, makes compliance integration expensive and sometimes impossible. Addressing these three failure modes is not a technical challenge. It is a planning and governance challenge, and it is where enterprise AI solutions most commonly break down.
ROI Measurement Framework
Before building: Define a baseline metric with the current-state measurement established. At 90 days and 6 months: Set KPIs tied to the baseline with clear owners. At 12 months: Separate operational efficiency gains from revenue impact.
Risks and Challenges in AI Development

Risk in AI development is not primarily technical. The failures that organizations should anticipate and plan for are organizational, regulatory, and structural.
Data Privacy and Model Bias
Models trained on historical data inherit the biases present in that data. In hiring, lending, healthcare, and criminal justice applications, this creates direct regulatory and reputational exposure. Deep learning models are particularly opaque; understanding why a neural network produced a specific output is genuinely difficult, which makes bias detection and audit harder. Data privacy risk runs in parallel: training on personal data without appropriate controls creates liability under GDPR, CCPA, and sector-specific regulations.
Talent Gaps and Workforce Readiness
Nearly half of executives cite workforce readiness as a key barrier to successful AI deployment, not technology limitations. (SmartDev) The bottleneck is rarely the availability of AI tools. It is the availability of people who can define meaningful use cases, evaluate vendor proposals critically, govern deployed models, and integrate AI outputs into existing workflows. NLP tools and accessible AI platforms have lowered the technical barrier significantly; the remaining barrier is organizational.
Vendor Dependency and Lock-in Risk
Vendor lock-in in AI development has a specific character that differs from traditional software. If a vendor retains ownership of the trained model, the training data, or the proprietary architecture, the switching cost for the buyer can be existential. Contracts must clearly define IP ownership of trained models, portability of training data, and the organization’s ability to retrain independently.
Regulatory Exposure
The regulatory landscape for AI is evolving rapidly across every major market. The EU AI Act, sector-specific US guidelines, and emerging frameworks in Asia-Pacific all carry different obligations around transparency, audit trails, human oversight requirements, and prohibited use cases. Organizations building AI systems now should assume more regulation, not less, over the lifetime of those systems.
AI Development Vendor Selection: An Executive Checklist
Vendor selection is where the fundamentals described above translate into due diligence questions. A vendor who cannot answer these questions clearly should not receive a contract.
- Domain-specific experience in your industry, with references to confirm it
- Defined data security and sovereignty policy for where data is stored, processed, and who has access
- Transparent pricing model with run-cost projections at the expected production workload
- Post-deployment monitoring and maintenance are included in the engagement scope
- Governance and compliance framework built into the development methodology
- Ownership of training data and model IP is clearly stated in contract terms
- Retraining cycle SLAs defined frequency, trigger conditions, and who bears the cost
- Client references with measurable, quantified outcomes, not testimonials
- Build vs. buy advisory capability, willingness to recommend off-shelf when appropriate
- Team structure clarified: dedicated team or shared resources across multiple clients?
Top Tools and Platforms Used in AI Development
The tooling landscape is large and changes quickly, but a relatively stable set of categories structures how AI development teams work. The following represents the current standard toolkit as a reference for evaluating vendor capability claims.
| Category | Tools |
| ML Frameworks | TensorFlow, PyTorch, scikit-learn |
| Cloud AI Platforms | AWS SageMaker, Google Vertex AI, Azure ML |
| MLOps | MLflow, Kubeflow, Weights & Biases |
| NLP / LLMs | Hugging Face, OpenAI API, Anthropic Claude |
| Data Pipelines | Apache Spark, Airflow, dbt |
Vendor familiarity with these tools is a baseline expectation, not a differentiator. What differentiates strong AI development partners is how they select and combine these tools to match specific organizational requirements and what happens when production workloads reveal that the initial architecture needs adjustment.
Emerging AI Development Trends Shaping Enterprise Strategy in 2026
The AI development landscape is shifting faster than most enterprise roadmaps can absorb. The following trends represent directional forces already affecting how organizations approach AI software development, vendor selection, and infrastructure investment in 2026.
Agentic AI Systems Are Moving From Pilot to Production
The most significant architectural shift in AI development in 2026 is the transition from single-inference models to agentic systems AI that can plan, take multi-step actions, use tools, and operate autonomously over extended workflows. Unlike traditional AI model deployment, agentic architectures require new governance frameworks, human-in-the-loop checkpoints, and audit trails that capture decision sequences, not just outputs.
Multimodal AI Is Redefining What “Input” Means
Multimodal AI systems process combinations of text, images, video, audio, and structured data in a single inference. For machine learning development teams, this expands what is buildable: quality inspection systems that combine visual and sensor data, customer service tools that process voice transcripts alongside CRM records, and document pipelines that handle tables, charts, and text simultaneously. Multimodal capabilities must now be evaluated during model selection, not added as an afterthought.
Small Language Models Are Challenging the Large Model Default
The assumption that larger models always produce better business outcomes is being challenged by a new generation of smaller, task-specific models that can be fine-tuned efficiently, deployed on-premise or at the edge, and operated at a fraction of the inference cost of frontier models. For enterprise AI solutions in latency-sensitive or data-sovereignty-constrained environments, such as manufacturing, healthcare, and financial services, small language models (SLMs) are increasingly the practical default.
AI Regulation Is Moving From Principle to Enforcement
The EU AI Act’s enforcement provisions for high-risk systems came into full effect in August 2025. In parallel, sector-specific guidance from the US NIST AI Risk Management Framework and emerging Asia-Pacific regulatory frameworks are establishing concrete audit, documentation, and human oversight requirements. For organizations engaged in custom AI development, this means governance frameworks must be designed into the development methodology from day one, not added during pre-launch review.
The compliance cost of retrofitting governance onto an existing AI system is approximately three to five times higher than building it into the original architecture.
Synthetic Data Is Closing the Training Data Gap
One of the most persistent bottlenecks in AI development is insufficient labeled training data, particularly in regulated industries or domains where rare events are underrepresented in historical records. Synthetic data, artificially generated data that preserves the statistical properties of real data without exposing sensitive information, is emerging as a viable solution. Organizations are now using it to augment training datasets for fraud detection, medical imaging, and autonomous systems.
MLOps Maturity Is Becoming a Vendor Differentiator
As AI deployment moves from experimental to operational, MLOps capability managing model deployment, versioning, monitoring, and retraining at scale is becoming a primary basis for vendor selection. Organizations that deployed AI systems in 2023 and 2024 without robust MLOps infrastructure are now facing the cost of retroactive instrumentation as those models decay. MLOps capability is no longer a nice-to-have; it is a baseline requirement evaluated during vendor selection.
Why Tibicle LLP Is a Practical Choice for AI Development
Tibicle LLP structures AI development engagements around measurable business outcomes rather than technology deliverables. That distinction matters because it changes where the accountability sits: not at model training completion, but at business metric movement.
The approach is governance-first compliance, and bias frameworks are designed into the development methodology rather than added afterward. Pricing is transparent, including run-cost projections at production workload. And the build-vs-buy advisory capability described in the checklist above is part of every initial engagement: if an off-shelf solution serves the use case better than custom development, that recommendation gets made regardless of what it means for contract value.
For organizations considering the hybrid model, internal oversight with external execution Tibicle LLP’s cross-industry experience covers the gap that most in-house teams cannot bridge alone: the translation between business requirements and production-ready AI software development.
See how Tibicle LLP structures AI development engagements built around measurable outcomes.
Conclusion
AI development ROI depends on clarity of objectives before the build begins. The fundamentals of data quality, governance, model fit, deployment planning, and ongoing monitoring matter more than the headline capability of any particular model or platform. The organizations that extract durable ROI from AI investment are those that get these fundamentals right before they worry about which architecture is generating the most coverage. Build vs. buy is a strategy decision, not a technical one, and most enterprises are best served by a hybrid approach that combines internal oversight with external execution capability.
Ready to define your AI development roadmap? Talk to Tibicle LLP‘s team and get a scoping assessment tied to your business goals. Schedule a call.
External Research Citations
The findings and statistics referenced throughout this guide draw on primary research from the following recognized sources. Organizations evaluating AI development investments are encouraged to consult the original publications directly.
| Source | Key Finding | Year |
| MIT Sloan Management Review | 95% of generative AI pilots are failing to scale | 2025 |
| Menlo Ventures | $18 billion invested in enterprise AI infrastructure | 2025 |
| Gartner | Only 21% of companies have fully scaled AI across business functions | 2025 |
| Shakudo | 65% of organizations abandoned AI projects due to governance failures | 2025 |
| S&P Global | 42% of companies abandoned most AI projects in 2025, up from 17% in 2024 | 2025 |
| McKinsey & Company | 42% of organizations apply AI in sales & marketing (highest by function) | 2025 |
| HypeStudio Research | Typical AI development ROI: 150–500% over two to five years | 2025 |
| SmartDev Enterprise AI Survey | 50% of executives cite workforce readiness as the primary deployment barrier | 2025 |
| IDC Worldwide AI Spending Guide | Enterprise agentic AI spending projected at $7.6B by 2028 (40%+ CAGR) | 2025 |
| Stanford HAI AI Index Report | Fine-tuned SLMs outperform large models on domain tasks in 73% of evals | 2025 |
Note: Citation accuracy reflects published research as of mid-2025. Readers should verify current figures directly with source organizations before using them in internal presentations or procurement processes.
Frequently Asked Questions
What are the fundamentals of AI development?
The core fundamentals include data pipeline design, model selection, training and evaluation frameworks, deployment infrastructure, AI governance, and ongoing monitoring. Each represents a distinct risk and cost surface that must be addressed for an AI system to perform reliably in production.
How much does custom AI development cost?
Custom AI development ranges from approximately $15,000 for simple NLP tools or chatbots to $300,000 or more for enterprise-grade AI platforms. Ongoing MLOps and maintenance typically runs $5,000–$25,000 per month depending on model complexity and retraining frequency.
What is the typical ROI timeline for AI development?
Most organizations see measurable ROI within 12–24 months of deployment. Narrowly scoped pilots with strong baseline metrics can show returns within 3–6 months. The 150–500% ROI range cited in research reflects the significant variance between well-governed projects and those that stall between pilot and production.
What is the biggest risk in enterprise AI development?
Governance gaps and poor data readiness are the leading causes of AI project failure, not technical limitations. The 42% project abandonment rate reported by S&P Global in 2025 is predominantly driven by these organizational and planning failures rather than model capability shortfalls.
Should businesses build AI in-house or work with a vendor?
It depends on three factors: how strategically important the use case is to your core product, whether you have genuine internal ML talent depth, and what your data sensitivity and sovereignty requirements are. Most enterprises benefit from a hybrid model that combines internal oversight and governance with external execution capability.
What is MLOps and why does it matter?
MLOps is the practice of managing AI model deployment, monitoring, and retraining in production environments. Without it, models degrade over time as real-world data drifts from the training distribution, a process that erodes accuracy, ROI, and eventually trust in the system. MLOps is what keeps deployed models performing at the level that justified the original investment.
Schedule A Developer Interview And Get 15 Days Risk-Free Trial
Schedule a Call
Relevant Blog

Top 7 Mobile App Development Company in India | 2026

Arjun Shinojiya

How to Hire Offshore Developers in 7 Easy Steps
Arjun Shinojiya

What is Product Engineering? A 2026 Guide to Success
Arjun Shinojiya
Written by

Recent Blogs
Key Fundamentals of AI Development | 2026 Guide
Introduction Ninety-five percent of generative AI pilots are failing. That figure comes from a 2025 MIT report, and it tells a very specific story: most organizations are investing in AI development without understanding what it actually takes to build systems that work at scale. For C-level leaders, AI development is not fundamentally a technical question. It […]
Top 7 Mobile App Development Company in India | 2026
Introduction Key Takeaway: India is the top global hub for a mobile app development company in 2026. The global mobile application market, valued at $252.89 billion in 2023, is projected to reach $626.39 billion by 2030 at 14.3% CAGR. Top Indian app developers deliver scalable enterprise products at budgets ranging from ₹4,00,000 to over ₹25,00,000. […]
How to Hire Offshore Developers in 7 Easy Steps
Introduction Key Takeaway: The offshore software development market reached $198.48 Billion in 2026. To hire offshore developers who actually deliver, you need a structured process: define your gaps, vet with live coding, lock down IP contracts, run a paid pilot, and invest in retention. Skipping any step increases your risk of wasted budget and missed […]
Got an Idea? Get FREE Consultation
In our world, there's no such thing as having too many clients